
Distributed Database System

- A distributed database is a system in which storage devices are not connected to a common processing unit.
- Database is controlled by Distributed Database Management System and data may be stored at the same location or spread over the interconnected network.
- It is a loosely coupled system.
- Shared nothing architecture is used in distributed databases.
- A distributed database is a collection of multiple interconnected databases, which are spread physically across various locations that communicate via a computer network.
- A distributed database is basically a database that is not limited to one system.
- A distributed database system is located on various sited that don’t share physical components.
- This may be required when a particular database needs to be accessed by various users globally.
- It needs to be managed such that for the users it looks like one single database.
- The basic types of distributed DBMS are as follows:
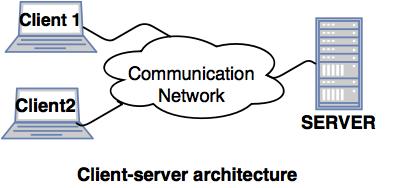
- 1. Client-server architecture of Distributed system.
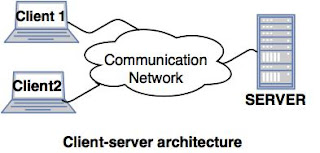
- A client-server architecture has a number of clients and a few servers connected in a network.
- A client sends a query to one of the servers. The earliest available server solves it and replies.
- A Client-server architecture is simple to implement and execute due to centralized server system.
- 2. Collaborating server architecture.

- Collaborating server architecture is designed to run a single query on multiple servers.
- Servers break single query into multiple small queries and the result is sent to the client.
- Collaborating server architecture has a collection of database servers. Each server is capable of executing the current transactions across the databases.
- 3. Middleware architecture.
- Middleware architectures are designed in such a way that a single query is executed on multiple servers.
- This system needs only one server which is capable of managing queries and transactions from multiple servers.
- Middleware architecture uses local servers to handle local queries and transactions.
- The software is used for the execution of queries and transactions across one or more independent database servers, this type of software is called middleware.
- Features
- Databases in the collection are logically interrelated with each other.
- Often they represent a single logical database.
- Data is physically stored across multiple sites.
- Data in each site can be managed by a DBMS independent of the other sites.
- The processors in the sites are connected via a network.
- They do not have any multiprocessor configuration.
- A distributed database is not a loosely connected file system.
- A distributed database incorporates transaction processing, but it is not synonymous with a transaction processing system.
- Types of distributed databases.
- 1. Homogeneous distributed databases system:
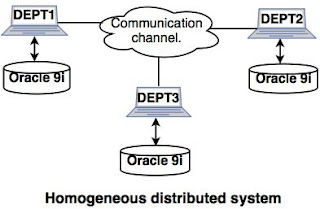
- The homogeneous distributed database system is a network of two or more databases (With the same type of DBMS software) which can be stored on one or more machines.
- So, in this system data can be accessed and modified simultaneously on several databases in the network.
- Homogeneous distributed system are easy to handle.
- Example: Consider that we have three departments using Oracle-9i for DBMS. If some changes are made in one department then, it would update the other department also.
- 2. Heterogeneous distributed database system.
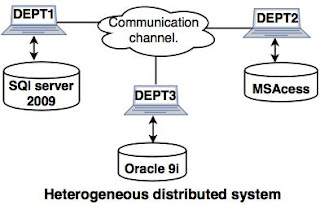
- The heterogeneous distributed database system is a network of two or more databases with different types of DBMS software, which can be stored on one or more machines.
- In this system, data can be accessible to several databases in the network with the help of generic connectivity (ODBC and JDBC).
- Example: In the following diagram, different DBMS software are accessible to each other using ODBC and JDBC.
- There are 2 ways in which data can be stored on different sites.
- 1. Replication
- Data replication is the process in which the data is copied at multiple locations (Different computers or servers) to improve the availability of data.
- Goals of data replication
- Data replication is done with an aim to:
- Increase the availability of data.
- Speed up the query evaluation.
- There are two types of data replication:
- 1. Synchronous Replication:
- In synchronous replication, the replica will be modified immediately after some changes are made in the relation table. So there is no difference between original data and replica.
- 2. Asynchronous replication:
- In asynchronous replication, the replica will be modified after commit is fired on to the database.
- Replication Schemes
- 1. Full Replication

- In full replication scheme, the database is available to almost every location or user in a communication network.
- Advantages of full replication
- High availability of data, as database is available to almost every location.
- Faster execution of queries.
- Disadvantages of full replication
- Concurrency control is difficult to achieve in full replication.
- Update operation is slower.
- 2. No Replication

- No replication means each fragment is stored exactly at one location.
- Advantages of no replication
- Concurrency can be minimized.
- Easy recovery of data.
- Disadvantages of no replication
- Poor availability of data.
- Slows down the query execution process, as multiple clients are accessing the same server.
- 3. Partial replication
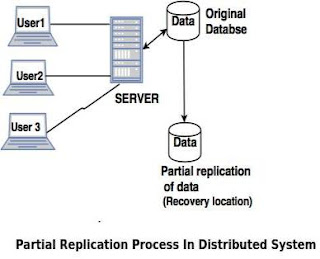
- Partial replication means only some fragments are replicated from the database.
- Advantages of partial replication
- The number of replicas created for fragments depends upon the importance of data in that fragment.
- 2. Fragmentation
- The process of dividing the database into smaller multiple parts is called fragmentation.
- These fragments may be stored at different locations.

- The data fragmentation process should be carried out in such a way that the reconstruction of the original database from the fragments is possible.
- There are three types of data fragmentation:
- 1. Horizontal data fragmentation
- Horizontal fragmentation divides a relation(table) horizontally into the group of rows to create subsets of tables.
- Example: SELECT * FROM Account WHERE Branch_Name= 'Pune' AND Balance < 50,000
- 2. Vertical Fragmentation
- Vertical fragmentation divides a relation(table) vertically into groups of columns to create subsets of tables.
- Example: SELECT * FROM Acc_NO
- 3. Hybrid Fragmentation
- Hybrid fragmentation can be achieved by performing horizontal and vertical partition together.
- Mixed fragmentation is group of rows and columns in relation.
- Example: SELECT * FROM Emp_Name WHERE Emp_Age < 40
- Advantages of Distributed Databases
- Modular Development − If the system needs to be expanded to new locations or new units, in centralized database systems, the action requires substantial efforts and disruption in the existing functioning. However, in distributed databases, the work simply requires adding new computers and local data to the new site and finally connecting them to the distributed system, with no interruption in current functions.
- More Reliable − In the case of database failures, the total system of centralized databases comes to a halt. However, in distributed systems, when a component fails, the functioning of the system continues may be at a reduced performance. Hence DDBMS is more reliable.
- Better Response − If data is distributed in an efficient manner, then user requests can be met from local data itself, thus providing faster response. On the other hand, in centralized systems, all queries have to pass through the central computer for processing, which increases the response time.
- Lower Communication Cost − In distributed database systems, if data is located locally where it is mostly used, then the communication costs for data manipulation can be minimized. This is not feasible in centralized systems.
- Disadvantages of Distributed Databases
- Need for complex and expensive software − DDBMS demands complex and often expensive software to provide data transparency and co-ordination across several sites.
- Processing overhead − Even simple operations may require a large number of communications and additional calculations to provide uniformity in data across the sites.
- Data integrity − The need for updating data in multiple sites pose problems of data integrity.
- Overheads for improper data distribution − Responsiveness of queries is largely dependent upon proper data distribution. Improper data distribution often leads to a very slow response to user requests.
- What is recovery in distributed databases?
- Recovery is the most complicated process in distributed databases. Recovery of a failed system in the communication network is very difficult.
- For example:
- Consider that, location A sends message to location B and expects response from B but B is unable to receive it. There are several problems with this situation which are as follows.
- Message was failed due to failure in the network.
- Location B sent message but not delivered to location A.
- Location B crashed down.
- So it is actually very difficult to find the cause of failure in a large communication network.
- Distributed commit in the network is also a serious problem that can affect the recovery in distributed databases.
- Two-phase commit protocol in Distributed databases
- Two-phase protocol is a type of atomic commitment protocol. This is a distributed algorithm that can coordinate all the processes that participate in the database and decide to commit or terminate the transactions. The protocol is based on commit and terminate action.
- The two-phase protocol ensures that all participant which are accessing the database server can receive and implement the same action (Commit or terminate), in case of local network failure.
- Two-phase commit protocol provides automatic recovery mechanism in case of a system failure.
- The location at which the original transaction takes place is called as coordinator and where the subprocess takes place is called as Cohort.
- Commit request:
- In the commit phase, the coordinator attempts to prepare all cohorts and take necessary steps to commit or terminate the transactions.
- Commit phase:
- The commit phase is based on voting of cohorts and the coordinator decides to commit or terminate the transaction.
- Concurrency problems in distributed databases.
- Some problems which occur while accessing the database are as follows:
- 1. Failure at local locations
- When system recovers from failure the database is outdated compared to other locations. So it is necessary to update the database.
- 2. Failure at communication location
- System should have a ability to manage temporary failure in a communicating network in distributed databases. In this case, partition occurs which can limit the communication between two locations.
- 3. Dealing with multiple copies of data
- It is very important to maintain multiple copies of distributed data at different locations.
- 4. Distributed commit
- While committing a transaction which is accessing databases stored on multiple locations, if failure occurs on some location during the commit process then this problem is called as distributed commit.
- 5. Distributed deadlock
- Deadlock can occur at several locations due to recovery problems and concurrency problems (multiple locations are accessing the same system in the communication network).
- There are three different ways of making distinguish copy of data by applying:
- 1) Lock based protocol
- A lock is applied to avoid concurrency problems between two transactions in such a way that the lock is applied on one transaction and other transactions can access it only when the lock is released. The lock is applied to write or read operations. It is an important method to avoid deadlock.
- 2) Shared lock system (Read lock)
- The transaction can activate shared lock on data to read its content. The lock is shared in such a way that any other transaction can activate the shared lock on the same data for reading purposes.
- 3) Exclusive lock
- The transaction can activate exclusive lock on a data to read and write operations. In this system, no other transaction can activate any kind of lock on that same data.






Tags:
DBMS
{kind=link}